
Since September 2021, Emilie has been working at Amplify Partners, an early-stage investment firm, where she is not involved in investment decisions. She has indicated Amplify portfolio companies referenced in this blog post with an asterisk.
As data practitioners, it is our responsibility to drive business impact through improved decision-making, not to impress fellow engineers with complex data pipelines. The JTBD (jobs to be done) framework can help data teams prioritize the right work and be more impactful in their day to day.
A single-minded focus on tooling and technology can lead to data practitioners losing sight of the most important thing: driving business impact through improved decision making. When I was leading the data organization at Netlify, I tried to help my team not lose sight of this by keeping our team mission front and center. It was at the top of every team meeting agenda and served as a prioritization framework for discussion. The Netlify Data Team Mission read:
The data team exists to empower the entire organization to make the best decisions possible by providing accurate, timely, and useful insights.
The way your team drives impact to the business is through improved decision-making- both for your company and your customers. While many people can conceptualize that, and rarely do I get any push back on the idea, it can be hard to take that mission and put it into practice. I often get asked: So, how exactly does my data team help drive improved decision-making?
I find that a great framework to lean on here is the “Jobs to be done” (JTBD) framework for understanding problems. In its simplest form, JTBD can be explained in the Henry Ford quote (which might not even be real), “If I had asked people what they wanted, they would have said faster horses.” In other words, listen not to the solution people are asking for, but rather understand the problems that need solving- and only then propose the best path forward.
This is also the best practice of product teams and underlies the thesis of Running Your Data Team like a Product Team. Understanding the core problems that data teams are solving for individual stakeholders is the crux of driving improved decision-making throughout your organization.
In my work with dozens of data teams over the past five years, I have seen a pattern of five JTBDs that they serve within the organization. With the proliferation of tooling in the Modern Data Stack, we are seeing the rise of dedicated software to solve some of these jobs individually. Put more directly, the proliferation of tooling is a result of understanding these jobs to be done. Tooling can not and should not dictate the work that data teams do, but this case of specialized tooling making it easier to solve problems that data teams are already trying to address can allow us to be more effective and more efficient in accomplishing our tasks.
In this blog post, I will share an overview of each JTBD, the problem it’s addressing, and the business impact of improving this pain point for your organization. I’ll also highlight some of the tooling that has popped up in recent years to address these JTBD. This post is not meant to be fully comprehensive of tooling and problems to be solved but instead to help those leading and organizing data teams understand the different ways their team might drive business impact.
It is also important to call out that there is work that your team must do that is not reflected in this framework. Managing data warehouse permissions, making improvements to CI, and building core data models are tasks that have to happen, but they are not the tasks that independently drive impact to the business. Sometimes they are prerequisites, but building a phenomenal chip is just a step toward creating the fastest computer in the world. I like to think of this work as enablement work- it drives impact to your team that allows you to impact the business, but it does not drive direct business impact.
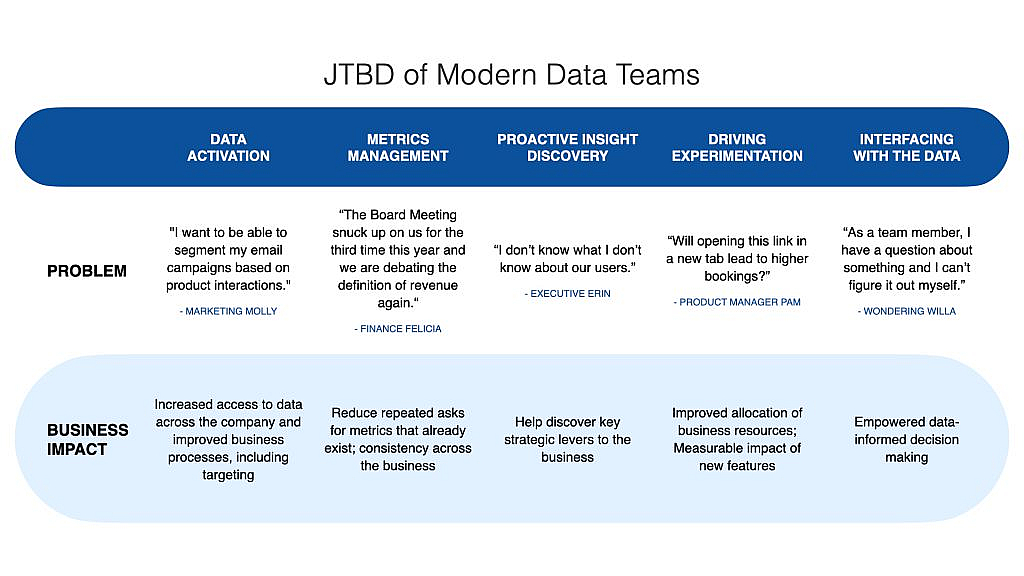
The five jobs to be done by modern data teams are:
- data activation – making operational data available to the teams that need it
- metrics management – the business needs shared definitions and a baseline of key metrics
- proactive insight discovery – team members outside of the data team are limited in the questions they can ask by their limited knowledge of what data exists and what questions can be asked
- driving experimentation – driving measurable impact to the business through A/B experimentation moving key business metrics in the right direction
- interfacing with the data – empowering team members across the business with the information and conclusions they need to be unblocked
Data Activation
A data team can have all the company’s data in the neatest, most well-organized data warehouse in the world. However, until it is driving action in the business, it isn’t having the impact it should be. Data activation empowers the business to harness the power of its internal data for applications that exist outside of the data team.
The most prototypical example to me of data activation comes from email marketers wanting to segment campaigns and messaging based on product interactions. It can be nearly impossible for reliable segmentation to occur in third-party tools. If the data warehouse is the single source of truth (SSOT) for your business on whether or not users successfully verified, then the only way to segment messaging around verification is to make the data from your warehouse available to your marketing team.
In my early career, we used BI tools that refreshed on a regular cadence to allow marketers to download CSVs, which they could then manually upload to their preferred tooling. This was fine but created extra work for many parties involved and could be error-prone, especially around holidays and vacations if queries were time-sensitive (e.g. show me only users who verified in the last week). Today, it is easier than ever to remove the human-in-the-loop and allow the data to be activated, or put to work for the business, improving outcomes with Hightouch*, Census, or Grouparoo. People can now spend their time writing better marketing campaigns and evaluating their performance instead of moving CSVs around, by letting SaaS tools move the data. Through data activation, we create one less step in the data distribution process for human error to be introduced.
Data activation is not just about making reporting and analytics data available for internal use cases. Predictions, recommendation systems, and advanced machine learning is a form of high maturity data activation. The data team produces the recommendation and then activates it by pushing it into other production systems, often empowering customers to make better decisions for themselves as they are being served better information than they would have had otherwise.
Metrics management
Does everyone in your company know what your North Star Metric is? Does everyone know how it’s measured? Do they know the difference between Active Users and Weekly Active Users? Or Revenue and Monthly Recurring Revenue? Does everyone know what your MRR was last month, and if you’re on track to hit this month’s target? Or whether conversion increased or decreased last month?
For many companies, data teams, often in collaboration with finance teams, are the keepers of the keys to the definition of core business metrics, where a definition is explained in both words and code.
The definition of Monthly Recurring Revenue might be:
revenue from subscriptions that are active on the last calendar day of the month; for yearly subscriptions, take 1/12 of yearly price per month that the subscription is active; excludes any non-subscription revenue.
It might also be
select date_trunc('month', transaction_date) as revenue_month,
sum(order_amount) as revenue_amount
from analytics.revenue
where subscription = true
group by 1
order by 1 descIt is the combination of these two parts of the definition that define and create metrics. The plain language without code can leave the data analyst stumped for where to start, and the code without the language can lose the nuances for team members looking to drive revenue. Together these create the definition of “Monthly Recurring Revenue” for an organization. And, without clear metrics definition management, your data team can get stuck redefining and getting buy-in on these metrics on a regular cadence.
Metrics management is not just about definition management, though. The data team should, in collaboration with business partners, drive regular metrics reviews, alert when metrics are off track, and drive root cause analyses to explain levers for improvement or what drove change. Metrics allow the company to have a shared understanding of reality- aligning on what is on track and what is not- and prioritize the limited resources of time and attention appropriately.
Metrics alignment across an organization becomes increasingly difficult as more folks work to drive improvements to metrics. Many companies have had success creating alignment in different ways. One route is for every metric to have a business and a technical owner who are together responsible for recertifying the metric definition on a regular cadence- at least quarterly. Your organizational context will help drive the best process for your company. Don’t be afraid to try various things to see what sticks.
With metrics definition management practices in place, possibly supported through metrics stores and headless BI platforms, such as Transform and MetriQL, data teams can help team members throughout the organization understand and take ownership of core KPIs, including being able to slice and dice them as needed with the goal of being able to truly understand what’s driving them.
Proactive Insight Dissemination
A common trap that data teams fall into is the reactive service model, where a stakeholder makes an inbound ask, someone creates a ticket, the data person answers the question in the ticket, and then moves on to the next one. This model necessarily constrains the data team to only focus on the question immediately in front of them instead of exploring the data to find valuable insights.
In a reactive model of answering questions for others, the data team takes someone else’s ideas and runs several analyses and regressions to find if there are any statistically significant correlations between the behaviors or combinations of behaviors and conversion in the appropriate time windows.
An example: in a software business, your data team is responsible for driving an understanding of your customer’s user journey including defining the “a-ha moment”- identifying what actions are taken in the first two weeks (or relevant time for your business) after a user’s sign-up would mean a high propensity to convert to paying customers in the first six months, similar to Facebook’s “10 friends in 7 days.“ This responsibility must lie with the data team because they are the only team with the unique combination of data, access, and technical expertise to make this analysis possible.
In a data team-led insight discovery model though, the data team recognizes that these sorts of questions- questions that can only be answered with advanced analysis- must be driven by the data team in collaboration with other parts of the organization. The data team is not just running the analysis for others; they are helping shape what questions are being asked. A product manager or engineer may, intentionally or not, limit their question scope based on what data they know exists. The data team member can enrich that with other sources and cross-functional data, as well. Moreover, with the data team driving, it is their responsibility to push the information to the organization. Instead of limiting the knowledge sharing to the stakeholder who asked the question, the data team is responsible for scaling knowledge within an organization.
Insight discovery can also build on top of the asks that others are making of the data team. It can be as simple as taking the existing task and scoping out just a little bit more discovery. For example, if you are tasked with trying to understand which email campaign is correlated with the highest open rates, you can expand that analysis to include which email campaign leads to the highest conversion rates- or how the open rates are or are not related to retention. Answer the right question, not just the one you were asked.
Driving Experimentation
When it comes to experimentation, data teams often rely on “growth” folks – product managers or growth marketing teams – to build and drive an experimentation practice. These often take a long time to get up and running because the technical infrastructure needed to drive experimentation takes a significant amount of effort and cultural buy-in to roll out. When the folks who are driving experimentation initiatives are removed from the technical requirements of experimentation, they hit additional barriers around communication.
Many data teams aren’t involved with experimentation at all. Or, if they are, they are only running analyses for experiments, explaining statistical significance and p-values, or, disappointingly, explaining how an infrastructure glitch led to a poor rollout. It takes many attempts to be able to successfully run an experiment. Even once you get there, they can be very resource-demanding from a time perspective.
Academic research demonstrates that experimentation can drive better performance for startups and help companies focus on moving the needle. Koning, Hasan, and Chatterji (2019) find that “A/B testing is positively related to tail outcomes, with adopting firms both scaling and failing faster.” Moreover, Kohavi et. al (2019) find that “only about 1/3 of ideas improve the metrics they were designed to improve”. Companies are shipping things that don’t matter and they can use experimentation to help identify those more quickly. Data teams can drive measurable impact through experimentation practices.
Data teams, as technical owners of metrics and partners to business owners of metrics, should be partnering with relevant stakeholders in an organization to roll out experiments that move those metrics. The data team is best poised to help evangelize the statistical knowledge required for running high-quality accurate A/B experiments and help stakeholders understand results. Automated A/B analyses from tools such as Eppo* and GrowthBook allow companies to adopt best-in-class experimentation practices with alerting around data quality and experimentation practices (without having to worry about explaining what a p-value is).
Interfacing with the data
Try as people might build the next “self-serve BI tool”, the data team is still the company’s most common interface to data. Whether it’s executives who will always just make asks for the things they’re interested in or navigating nuances of the data that drag-and-drop interfaces don’t capture, the data team can be the primary interface for data for the company. The data team has to help team members access data, understand the underlying mechanisms that produce it, and synthesize what it means.
This is service work. The number of requests inbound to the data team will scale linearly with company headcount. For a team to scale non-linearly with headcount, this service work must be addressed in a way that minimizes it as a portion of the work the data team does and looks for opportunities to make this work less manual. Given the number of questions coming at a data team, we need to be able to prioritize questions based on impact, understand what the tradeoffs of taking a task on are, and ensure we are building to solve problems, not just building requested solutions. This work can manifest in several ways: in ad hoc dashboards, in presentation decks, in recurring meetings, or in pairing sessions.
Where GUIs fail, the data team is the abstraction layer for understanding and interfacing with the data for the company. The data team is the Swiss Army Knife of interfacing with the data for the company. Traditional business intelligence tools like Looker, Mode, and Tableau have tried to fill this gap, but no amount of tooling will ever replace domain expertise. Figure out an intake mechanism that works for your company and focus on driving impact.
Impact first, cool tooling second.
Before, all we had was a Business Intelligence Tool-shaped hammer to solve many different problems for our organizations as our data teams.
The explosion of tooling in the data space is a result of a better understanding of exactly the problems we are solving for organizations. Today we have a whole toolkit of dedicated solutions helping us best address the ways that our data teams impact the business.
I get excited by all of the new tooling. New companies, new ideas, new problems- they are exciting! But, we cannot obsess over the tooling and lose sight of the work: driving impact through improved decision making.




